操作系统概念总结

操作系统
复杂指令集(cisc)
CPU位数 = CPU中寄存器的位数 =数据总线位数= CPU一次并行处理的数据宽度 ,CPU位数 >=操作系统位数 ,地址总线位数决定了CPU在内存中的寻址能力
8086 16位
x86 32位
IA-32 32位
x86-64 x64 intel64 amd64 均为64位,代表同一个指令集
精简指令集(risc)
arms
mips
risc-V
大小端存储
大端是高位字节低地址,小端是高位字节高地址。注意数据是左高右低,即按字节划分数据,左边为高位
例: rax = 0x12345678
对于 mov dword[bin_num + 4] , rax 这个指令将rax寄存器中的内容存入内存,x86是小端架构,先将寄存器高位的字节存到内存的高地址空间,那么内存中从低位bin_num+1到高位的bin_num+4就是这个样子 : 78,56,34,12
8086寄存器种类
数据寄存器: ax(累加寄存器) bx(基址寄存器) cx(循环计数寄存器) dx(数据寄存器)
指针寄存器: sp(栈顶指针) bp(基址指针)
变址寄存器: si (源地址寄存器) di(目标地址寄存器)
段寄存器: ds(数据段寄存器) cs(代码段寄存器) ss(堆栈段寄存器) es(附加寄存器)
控制寄存器: ip(指令寄存器) flag(标志位寄存器)
注意:
栈顶指针总是指向一个数据而不是下一个空位,即push ax是先将sp-2 再向ss:sp中送入数据。
栈顶在低地址,栈底在高地址,栈从高地址向低地址生长
sp存储的是相对于栈顶的偏移地址,栈顶的地址存在于ss中(堆栈段的起始地址)
ip存储的是相对于代码段初始位置的偏移地址,CPU当前执行的指令是cs:ip
在指令中给出的地址都是偏移量,对应段基址是默认自动加上的,也可以显式的使用段超越的方式说明
如mov ax , es:[3000H] 显式使用附加段es
几乎每个通用寄存器都有它的特殊用法,这点通过他的名称可以看出
8086寻址方式–寻找指令所需操作数
立即寻址 mov ax,8
寄存器寻址 mov ax,bx (bx保存了操作数8)
直接寻址 mov ax,[0x8890] 0x8890是段内偏移量 直接给出 也可用变量代替
寄存器间接寻址 mov cx, [bx] bx中保存了段内偏移地址,默认为数据段,si,di寄存器均默认数据段
bp名义上不能间接寻址 只是默认偏移量为0的相对寻址,且bp默认为栈段的偏移量寄存器相对寻址 mov cx,count[bx] 或 mov cx,[bx+count] 即在寄存器间接寻址的基础上在偏移地址多加一个偏移量count
基址变址寻址 mov cx,[bx+di] 使用一个基址+一个变址作为偏移量使用,段地址由基址寄存器来确定
基址变址相对寻址 mov cx,count[bx+di] 在基址变址的基础上增加一个偏移量count
汇编中三种函数传参方式
- 通过指定寄存器传参
- 通过指定内存空间传参
- 通过栈传参
如:
1 | push ax ;占据2byte |
x86汇编的两种风格
1. 语法结构
- Intel 风格:
- 操作数顺序:指令通常是
操作码 目的, 源,例如:MOV EAX, EBX。 - 使用
[]表示内存地址,例如:MOV EAX, [EBX]。 - 常量与寄存器比较简单,不会添加额外的前缀。
- 注释为 ;
- 操作数顺序:指令通常是
- AT&T 风格:
- 操作数顺序:指令通常是
操作码 源, 目的,例如:movl %ebx, %eax。 - 使用
()表示内存地址,例如:movl (%ebx), %eax。 - 寄存器名前加
%符号,指明这是一个寄存器。 - 注释为 #
- 操作数顺序:指令通常是
2. 数据大小
- Intel 风格
- 数据大小通常是隐式的,操作指令会自然理解操作的数据类型(如字节、字、双字等)。
- AT&T 风格
- 数据大小在操作码中明确指定,一般用后缀表示,如
b(字节),w(字),l(双字),如movb,movw,movl。
- 数据大小在操作码中明确指定,一般用后缀表示,如
3. 常量表示
- Intel 风格:直接使用数字,如:
MOV EAX, 5。 - AT&T 风格:常量前加
$符号,例如:movl $5, %eax。
操作系统的启动过程
org address 伪指令
如org 07c00h,写在汇编代码的开头,告诉当前这段代码会放在07c00h处。所以,如果之后遇到需要绝对寻址的指令,那么绝对地址就是07c00h加上相对地址。
• 绝对地址:内存的实际位置(先不考虑内存分页一类逻辑地址)。
• 相对地址:当前指令相对第一行代码的位置。
int 10h终端调用
BIOS对屏幕所提供的显示服务。使用int 10H中断服务程序时,先要进行一些简单的配置,比如指定功能号和子功能号。其中寄存器AH表示的就是功能号,AL是子功能号,当一切设定好之后再调用 int 10H。
此时中断处理使用中断向量表,是Bios提供中断处理程序
磁盘位置分配
早期的16位Intel 808处理器只能寻址1MB的物理内存(16位段寄存器地址左移4位+偏移量)。所以早期PC的物理地址空间将从0x00000000开始,到0x000FFFFF结束,而不是0xFFFFFFFF(32位)。
标记为Low Memory的640KB空间是早期PC能够使用的唯一随机访问内存(RAM)。
640KB到1MB之间的区域由硬件预留,用于特殊用途,如视频显示缓冲区(显存)和一些系统固件。
这个保留区域中最重要的部分是**Basic Input/Output System (BIOS)**(硬件厂商在硬件上自带的一段启动的代码),它占用了从0x000F0000到0x000FFFFF的64KB区域。
早期BIOS保存在真正的只读存储器(ROM)中,但现在的PC将BIOS存储在可更新的闪存中(不管是闪存还是ROM,都是在主板上)
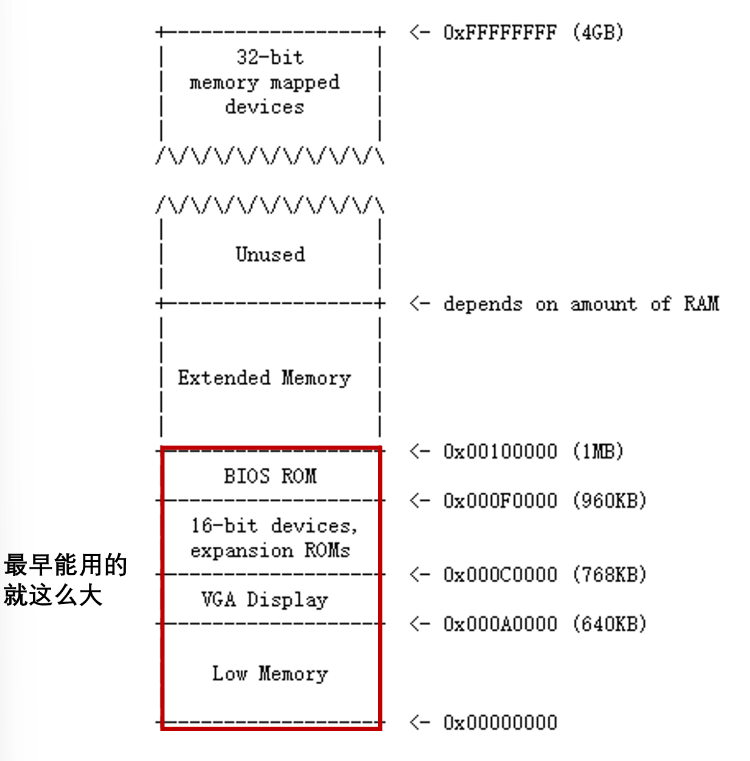
随着技术的发展,Intel最终使用80286和80386处理器突破了1MB的寻址,它们分别支持16MB和4GB的物理地址空间,但PC架构师仍然保留了原始的1MB物理地址空间布局,以确保与现有软件的向后兼容性。
因此,现代pc在物理内存中有一个从0x000A0000到0x00100000的一个洞,将RAM划分为 “low memory” 或 “conventional memory” (前640KB)和 “extended memory” (其他的部分)。
Bios的全过程
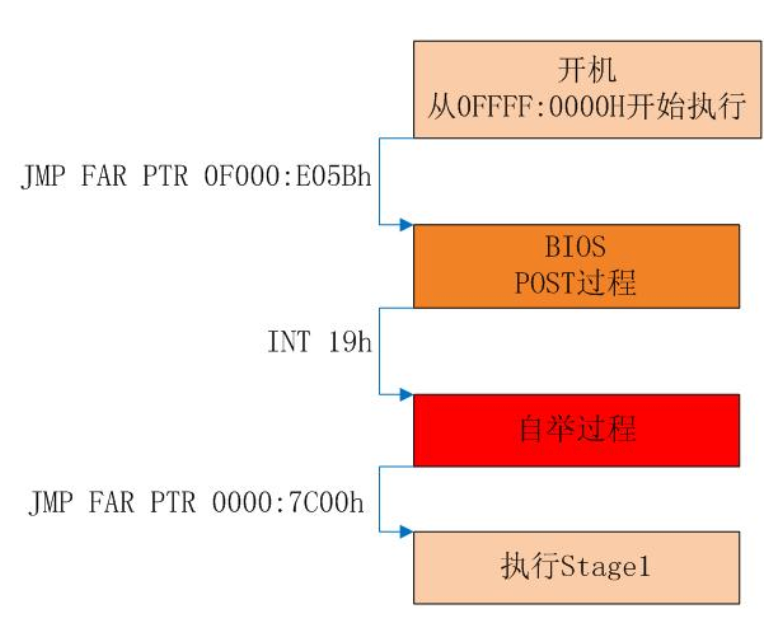
开机第一条指令:在物理地址 FFFF0H(等价于0FFFF:0000H)处执行跳转指令(这是硬件厂商规定的地址,操作系统必须按照这个来) 将指令指针寄存器跳转到BIOS代码所在的位置,开始执行BIOS程序;
POST(自检)过程:负责对系统进行基本的检测和初始化操作,如激活显卡、检查内存安装量等。
自举过程:BIOS从一些适当的位置(比如硬盘)加载引导程序,检查魔数(第0磁头 第0磁道 第1扇区是否以0x55aa两个字节结尾)把MBR的内容从磁盘调入内存地址为0x7c00的地方,关闭保护模式,回到实模式
最后跳转到7c00h这里,执行MBR代码。
总结:加电后的第一条指令都是跳转到BIOS代码进行开机自检,完成后寻找可启动设备(处于实模式):引导MBR进入内存并执行MBR,而MBR要进入保护模式并将OS内核加载到内存中,并跳转到这个内核的执行代码。 我们能编程的地方就是MBR和OS内核,但是有些人认为MBR512字节太小,不够编程使用,所以就又加入一个loader,先用MBR加载loader,再用loader加载内核。
内存区更详细的补充:
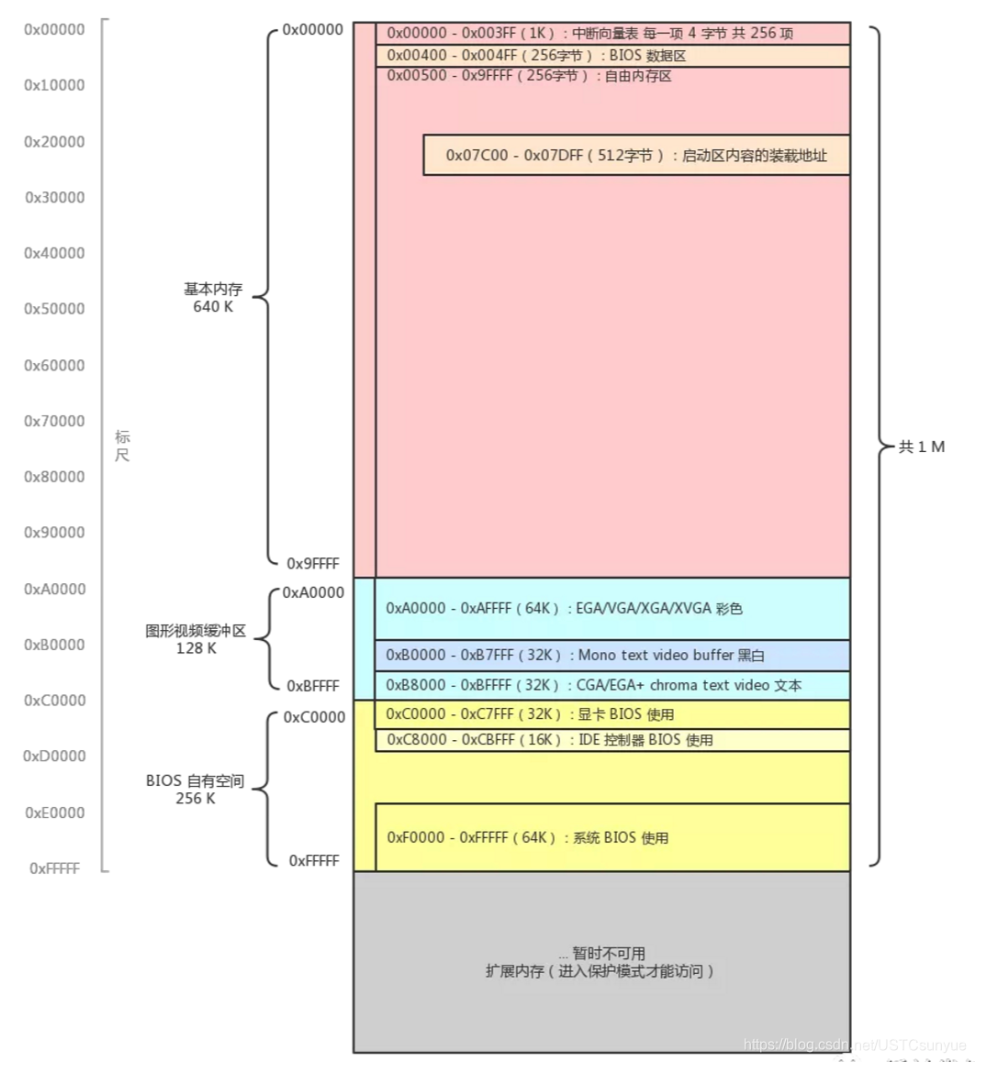
各个段寄存器在最开始保存什么内容? 不固定,而且可以设置,不用太注意
可执行的MBR
刚刚我们的mbr.S是怎么变成可以被QEMU执行的MBR的呢?
说到底原理其实很简单,MBR本质就是一串可以被执行的指令再加上魔数。
所以只需要先编译成可执行文件,再把里面的指令抽出来,最后再加上魔数就可以了。
所以首先用gcc把mbr.S编译成.o的可重定位文件,然后再用ld链接成可执行的ELF文件,然后我们要从ELF里抽取指令,指令都在.text节里,可以用objcopy抽取然后以二进制文件的形式存在一个bin文件里。
最后我们用一个小脚本genboot.pl来给这个文件扩充成510字节再填充最后的魔数,就得到我们的MBR了。
保护模式下的寻址
实模式到保护模式
设置段表GDT,再设置CR0寄存器最低位为1
GDT:包含很多段描述符
1 | +----------------+ |
段描述符:
注意 这里默认低位要放到低地址 和大端小端无关。
1 | DESCRIPTORS USED FOR APPLICATIONS CODE AND DATA SEGMENTS |
寻址过程
通过GDTR得到GDT的首地址和限长(在将GDT设定在内存的某个位置后,可以通过 LGDT 指令将GDT的入口地址装入此寄存器。)
1 | GDT REGISTER (GDTR) |
首先给出48位逻辑地址(虚拟地址), 其中包含了高16位的段选择子(从段寄存器中得来)和低位的段内偏移地址(也就是程序中写的地址),使用段选择子找到对应段的起始地址,加上偏移地址就是线性地址了
1 | 段选择子 |
- 首先看段选择子第三位是0还是1,分别对应GDT和LDT方式寻址
- 如果是GDT 先要在GDTR(48位)中找到内存中GDT表的起始地址,然后加上段选择子中13位偏移量取得段描述符,得到目标段的起始地址,然后加上一开始的段内偏移量即可得到线性地址
- 如果是LDT,首先还是在GDTR寄存器中获得GDT起始地址,但是要用LDTR中的偏移量作偏移
,得到对应整个LDT的段描述符(对应的LDT的起始地址),然后再重复上面的操作,在LDT中得到目标段的描述符,用其中的起始地址+偏移量得到线性地址(多做一些预备操作)
总结:GDT中保存了系统段描述符和用户(进程)对应的LDT的描述符(注意是一整个LDT),而LDTR中时刻保存本进程的LDT在GDT中的选择子,可以用LDTR找到存在于GDT中的LDT描述符,进而找到目标LDT的起始内存地址。
(段选择符在段寄存器中 任何变量在创建时的地址都是偏移量 需要+本段的段选择符对应的段基址才可以)
Linux的可执行文件ELF
我们可以将ELF可执行目标文件看作由三个部分组成:ELF头、程序头表、其余的ELF文件体。
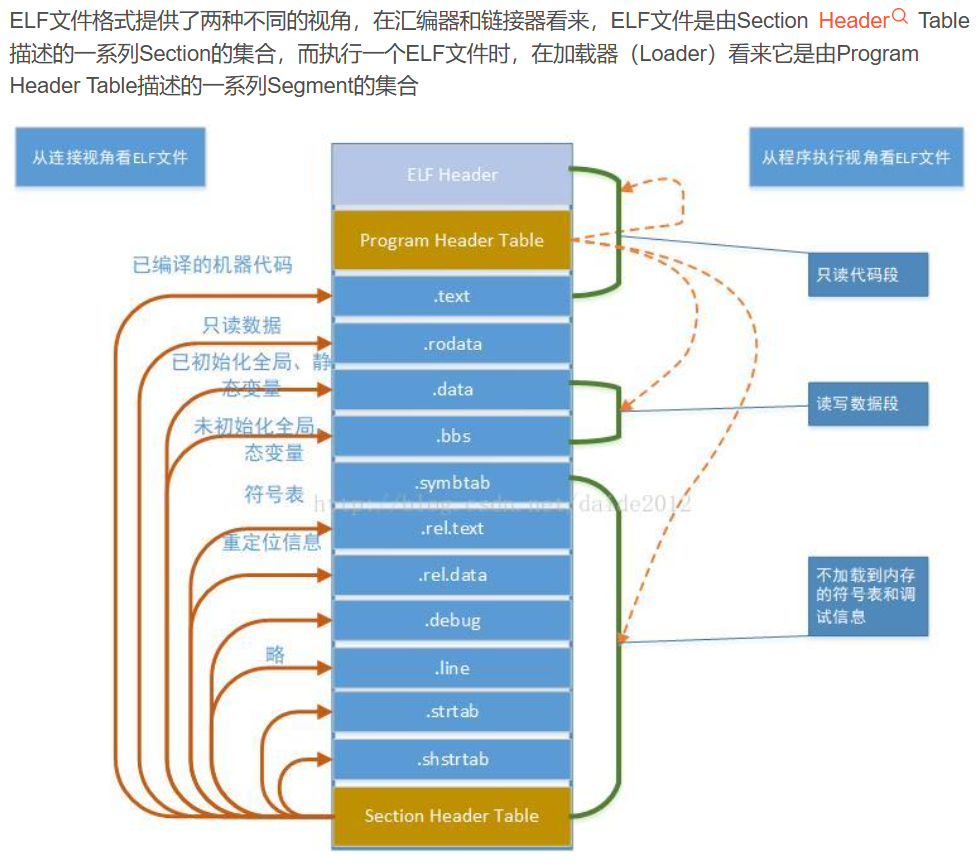
在汇编程序中用.section声明的Section会成为目标文件中的Section,此外汇编器还会自动添加一些Section(比如符号表)。Segment是指在程序运行时加载到内存的具有相同属性的区域,由一个或多个Section组成,比如有两个Section都要求加载到内存后可读可写,就属于同一个Segment。
有些Section只对汇编器和链接器有意义,在运行时用不到,也不需要加载到内存,那么就不属于任何Segment。
目标文件需要链接器做进一步处理,所以一定有Section Header Table;可执行文件需要加载运行,所以一定有Program Header Table;而共享库既要加载运行,又要在加载时做动态链接,所以既有Section Header Table又有Program Header Table。所以ELF文件既可以是目标文件.o ,也可以是可执行文件。
#####下面注重可执行文件ELF的介绍
ELF头的结构:一个结构体
关键部分:
1 | ElfN_Addr e_entry; // 程序的入口地址 |
ELF program table表项结构
关键部分:
ELF文件的装载
装载的过程简言之就是将ELF文件中的程序和数据段等需要装载到内存中的segment拷贝到内存中合适位置的过程。在ELF文件中存储了一个数组,叫做程序头表(program header table),其在ELF文件中偏移量由ELF Header中的e_phoff域给出。
程序头表也是一个结构体:
其中,p_type指定了表项的类型,对于类型为PT_LOAD类型的表项,我们需要对其进行装载。
装载过程可以简述为,对于p_type == PT_LOAD的表项,将ELF文件中起始于p_offset,大小为p_filesz字节的数据拷贝到内存中起始于p_vaddr的位置,并将内存中剩余的p_memsz - p_filesz字节的内容清零。
readelf命令查看ELF文件的内容,readelf提供了两个视角,一个是面向链接过程的section视角(readelf -S),另一个是面向执行的segment视角(readelf -l)。在这里我们关注后一个视角即可。
总结装载过程:
- 读入位于ELF文件最开始位置(偏移量为0)处的ELF头,并根据其中的值e_phoff定位程序头表在ELF文件中的位置;
- 顺序扫描程序头表中的每一个表项,遇到需要装载的表项时,根据表项描述的内容将相应的数据拷贝到内存相应位置。
ELF文件指令
readelf -a 显示全部内容
readelf -l 显示segment
readelf -S 显示section
objdump -d 反编译二进制文件,如可执行elf文件
例如:objdump -d kernel > 1.txt // 内容输出到1.txt
动态链接和静态链接
编译阶段:首先,源代码文件被编译器编译成对象文件(通常是.o或.obj文件),这些文件包含了程序代码的机器语言表示,但还没有解决外部引用。
链接:将目标文件(包含可重定位目标程序,从汇编翻译得到的机器语言)中使用到的库函数或者其他不包含在该文件中的函数(及数据)链接到该文件中,符号解析伴随这个过程;将每个符号的定义与具体在内存中的位置进行关联(重定位,将变量偏移量即相对地址变为虚拟地址?),发生了空间和地址分配。
目标文件(.o)三种格式:
- 可重定位目标文件:包含二进制代码和数据,其形式可以和其他目标文件进行合并,创建一个可执行目标文件
- 可执行目标文件:包含二进制代码和数据,可直接被加载器加载执行
- 共享目标文件:可被动态的加载和链接
静态链接——链接时,将库代码全部加入到可执行文件
- 制作静态库文件
1 | ar -cvr libmylib.a my_lib.o # 静态库文件以lib开头 .a作为拓展名 libXXX.a |
- 链接
1 | ld -o test test.o -L ./ -lmylib # test.o是主文件 -L指定库文件的路径,-l之后紧接着库文件名(去掉开头lib和结尾.a) |
注意!使用 ld 而不是 gcc 这意味着必须手动指定所有链接时需要的系统库和路径,因为 ld 不会像 gcc 那样自动添加标准的系统库和其他必要的链接选项。
动态链接——在执行时,链接文件加载库
进程
进程是对程序一次运行的抽象,进程管理了进程运行所需要的各种资源。
进程的管理依靠进程控制块(PCB)
中断
中断向量
在实模式下,针对每一种中断源,标记1种中断向量,共256个,中断向量顺序存储在内存特定的位置,包含了中断程序的起始地址。 程序通过int指令+中断类型码实现调用中断程序。相应中断时,由中断系统硬件计算并提供具体向量地址,处理机根据地址转入相应的中断程序。
我们把每个中断服务程序进行编号,这个号就代表一个中断服务程序,就是中断类型码。这个中断类型码是计算机用来查找中断向量用的。
中断向量表是8086内存中最低的1K空间,保存了256个中断向量,每个4B,低位存偏移量,高位是段地址 通过实模式寻址方式找到入口程序。 前32个中断硬件系统预留 后224个自定义。
中断描述符表 IDT
在保护模式下,存在于内存中,其中保存了中断描述符(8字节)。每个中断或者异常对应一个中断描述符,共256个,占用2K空间,也是通过中断类型码得到对应的中断描述符,中断描述符记录了中断程序的起始地址, 属性等等信息,共分为任务门,中断门和自陷门,CPU对不同的门处理方式不同。中断描述符表的起始地址通过全局描述符表制定。可以通过访问中断描述符访问中断程序。
CPU提供了IDTR存储IDT的首地址,和GDTR一样包含了32位基地址和16位段限 实模式的中断向量表是固定在存储器的最底部,而保护模式下的IDT则是可以改变的
保护模式下,需要两次查表来获得中断服务子程序的入口地址。
- 首先通过IDTR查询到IDT的位置 然后通过中断类型码8(偏移量)加上IDT的基址*得到中断描述符的位置
- 中断描述符自己记录了段选择符和对应的偏移量,直接通过段选择符找到段的基地址+偏移量得到代码段的地址。
找到入口地址,还需要保存现场(在下面有更详细的描述):
- 如果当前处于用户态,将栈指针切换到内核栈栈顶后压栈旧的SS和ESP,再进行第2步,否则直接进行第2步
- 依次将EFLAGS(32位),CS(扩充到32位),EIP(32位)寄存器的值压栈,对于某些异常,还会再压栈一个错误码(也是32位);
注意:对于int指令主动陷入的中断,压栈的EIP指向的是int的下一条指令——要不然返回后还是那条int指令,出不去了; - 如果门描述符的TYPE是中断门,清除EFLAGS的IF位(即关中断)
- 跳转到中断处理程序的入口地址。
门描述符结构
1 | 80386 GATE DESCRIPTOR |
P位是有效位,1即该门有效。
SELECTOR和OFFSET就是入口地址,之前我们学过,在保护模式中,是由CS和EIP共同承担PC的任务,而入口地址的CS就是这个SELECTOR,EIP就是OFFSET。CS:IP=当前执行的指令地址
DPL就是这个门描述符的权限,设为0表示不允许用户程序主动通过int指令陷入这个中断,设为3表示允许用户程序主动通过int指令陷入这个中断。
注意这个权限仅限制主动陷入的情况,对于强制中断(异常、外部中断),则不需要检查权限。
TYPE分为两种:
- 0xE即中断门(Interrupt Gate),这种门对应的中断在响应时还会顺手把中断关了,避免后续处理时由外部中断引发的中断嵌套,外部中断应该使用这种门。
- 0xF即陷阱门(Trap Gate),这种门对应的中断在响应时不会改变中断开关的状态,系统调用和异常理应使用这种门。
中断类似函数调用:将状态保存之后再跳转。就像函数调用通过ret指令返回,中断处理结束之后的返回指令iret也是类似的——依次弹栈EIP、CS和EFLAGS并恢复,一般是恢复到中断之前的位置
中断分类
包含异常和狭义中断(两者可以统称为中断)。中断是CPU以外发生事件;异常通常是指程序中指令执行出现了错误等CPU内部事件引起的过程。异常进一步可分为错误(fault)陷阱(trap)中止(abort)。陷阱一般指程序中的硬件中断调用,错误是可更正的程序执行错误,一般保留产生fault的指令的地址继续执行。abort则是严重错误,程序不能继续执行。
异常的常见情况(不可屏蔽):错误或者硬件故障或者是程序执行int指令(软中断/系统调用)。外部中断,可分为可屏蔽中断和不可屏蔽中断。
共同点:都是程序执行过程中的强制性转移,转移到相应的处理程序。都是软件或者硬件发生了某种情形而通知CPU的行为。
区别
- 中断,是CPU所具备的功能。通常因为“硬件”而随机发生。
异常,是“软件”运行过程中的一种开发过程中没有考虑到的程序错误。 - 中断是CPU暂停当前工作,有计划地去处理其他的事情。中断的发生一般是可以预知的,处理的过程也是事先制定好的。处理中断时程序是正常运行的。
异常是CPU遇到了无法响应的工作,而后进入一种非正常状态。异常的出现表明程序有缺陷。 - 中断是异步的,异常是同步的。
- 中断是来自处理器外部的I/O设备的信号的结果,它不是由指令流中某条指令执行引起的,从这个意义上讲,它是异步的,是来自指令流之外的。
- 异常是执行当前指令流中的某条指令的结果,是来自指令流内部的,从这个意义上讲它们都是同步的。
特权级别:ring 0被叫做内核态,完全在操作系统内核中运行。 ring 3被叫做用户态,在应用程序中运行
注意
找到中断处理程序进行中断之前,EFLAGS,CS,IP自动由硬件保存;错误码、中断号、通用寄存器、DS,等得自己在实现的操作系统中断程序中进行保存(压栈),SS,SP视情况而定,若是用户态到内核态则需要将栈指针切换到内核栈栈顶后压栈旧的SS和ESP,因为要进行栈的切换。若是内核态到内核态的中断,则不需要。通过将esp压入栈,可以认为是传递一个以上寄存器上下文的指针,方便对这些寄存器的访问。(很关键)
CPU通过CS:IP寄存器确定指令的位置
CPU通过DS:[address]确认数据的位置
SS:SP 确定栈顶的位置。
iret指令的解释 (从中断恢复现场)
从栈中弹出指令寄存器的值放入esp,弹出代码段选择子放入cs,弹出程序状态字放入Eflags中。(硬件完成)
如果返回的进程保护级别不同的话,需要进行栈的切换,还需要弹出栈顶指针到esp,栈段选择子到ss(esp是偏移地址 保存了栈顶元素地址 例如push先减去4才能将eax压入栈)弹出寄存器的顺序是严格的,iret自动执行,不用手动执行
而通用寄存器,DS,ES都是得手动pop的,要使用到之前压入的esp,顺序和上面提到的压入顺序相反,所以这部分内容要在iret执行前完成,注意额外为esp加几个字节,跳过中断号和错误码。
内核栈和TSS 任务状态段
在中断发生时,不能信任用户程序的栈指针的值,否则压栈保存现场时可能出现页错误!因此,操作系统需要准备一个自己的栈,在进行任何栈操作之前(包括保存上下文),操作系统都需要先把栈指针指向自己准备的栈的栈顶。这个栈我们称之为内核栈,而相对地,用户程序的栈我们称为用户栈。
注意这种“栈切换”的操作是只有从用户态到内核态的中断才需要进行,而内核态到内核态的中断是不需要的(不存在用户态到用户态或者内核态到用户态的中断)。
为啥内核态中断不需要切换?因为如果每次都都是先把栈指针指向内核栈顶的话,相当于每次都把信息保存在一个固定的地方,那么一旦发生中断嵌套,后保存的信息就会把先保存的信息给覆盖掉。而且操作系统的esp是可以相信的,不需要切换栈来防备它。
而只在用户态到内核态的中断进行栈切换就没有这个问题,即使后续发生中断嵌套,后续中断保存的信息是压在新的内核栈里的,不会覆盖或被覆盖。
“栈切换”过程:
判断现在的状态:在i386,我们使用CS段寄存器的低2位来判断——0就是内核态,3就是用户态;
内核栈放在哪:TSS段(任务状态段,跟进程内核栈相关)。TSS里有两个域
ss0和esp0,就是指向内核栈栈顶的位置(正如i386使用CS段寄存器和EIP寄存器联合确定pc位置,栈的位置也是由SS段寄存器和ESP寄存器联合确定);保存用户栈的位置:中断返回时要恢复。保存在哪里?是中断上下文。
所以中断上下文中要保存用户栈的ss和栈指针寄存器,用于恢复现场。但是从内核到内核的嵌套中断中,这两个被保存的寄存器就失去了意义,可以无视。(SS和ESP成员指向的就是不属于这个上下文的地方,所以既没有意义也不能修改。)
ATTENTION!:内核栈栈指针esp和内核栈段选择子ss被保存到TSS后,之后每次用户态中断都会自动使用TSS中的ss:esp来保存现场,避免了位置错误引发的页错误
如何进入第一个用户程序?
在跳转到用户程序时,我们还需要修改段寄存器的值,还有就是操作系统要准备一个内核栈并设置在TSS中。手动构造一个返回到用户态的中断上下文,然后用它“假装”进行中断返回,这样最方便(从内核态到用户态)。
每个进程控制块都要有一个中断上下文和一个内核栈 来在中断中使用。
内核栈和中断上下文的组织方式:
1 |
|
内核栈联合体大小为4096个byte,正好是一页。前面的部分是真正的内核栈,后面的部分是中断上下文,中间的部分就是pad数组填充的剩余区域。
这样组织的优点:使用联合体可以节省内存,因为内核栈和中断上下文共享相同的内存区域。这种方式在需要频繁进出中断的上下文时,避免了多次分配和释放内存的开销。
1 | void proc_run(proc_t *proc) { |
补充资料:Linux下的TSS使用
原来Linux只用Tss的ss0和esp0!!

外部中断
主要在操作系统中实现串口中断(外部输入导致中断),时钟中断。
系统调用
操作系统为用户程序提供的一组API,可以实现对硬件等高特权级资源的操作,通过内核函数,也称作服务例程所实现。系统调用有它自己的中断号,通过系统调用号实现具体历程的调用。进行系统调用时,首先进行中断,进行相应的中断处理程序,然后查看系统调用号,访问相应的系统调用例程。
内核函数:是在内核态即处理中断或异常(int指令)时 处理器程序状态字自动被cpu被设置为内核态,此时执行的例程。可以使用比用户态更多的指令,如sti,cli等
约定
进行系统调用时,要进行一些约定,主要是提供该系统调用的参数存放在什么位置,如系统调用号存在eax中。自洽即可。
注意
(其实这里可以看到,syscall保存寄存器这样的任务,我们在讲述或者理解的时候,往往把这些任务看作一个整体。但是实际上,我们在处理这些功能会通过操作系统与硬件、用户程序与操作系统的约定,来划分各自不同的职责。我们在实现这些与硬件相关的操作系统功能时,一定要区分什么事情是操作系统需要做的,什么事情又是硬件来处理的。类似的例子是分页机制,操作系统负责对页表、页目录的维护,指令执行时的地址转换是由硬件MMU自动完成的。)
1 | 操作系统的实现是理解硬件职责与约定下的底层软件编程 |
调用者保存与被调用者保存
callee saved(被调用者保存,负责压栈出栈)
ebx ,ebp,
caller saved(调用者保存,调用者负责压栈和出栈。)
eax,edi,esi,edx,ecx,
i386的函数调用机制:调用者从右向左压栈,被调用的函数如果参数个数比压栈的少就相当于只取前几个参数,并且使用后参数的出栈是由调用者负责——压几个弹几个,所以也不会造成栈的不平衡;至于返回值,就相当于调用完后直接取EAX寄存器的值,反正肯定是能取到的。
上面这么做有个前提就是所有参数和返回值都是32位、4字节的,不过我们的系统调用都满足这个前提。
分页
在i386这样的分页式虚拟存储中,主存地址和虚拟地址空间都被划分成大小相等的页面,在虚拟地址空间中的页面称为虚拟页,而对应的在主存空间中的页面称为物理页。
x86系统中,规定每个页面的大小为2^12 = 4KiB (低12位)。于是一个虚拟地址空间就被划分成 2^20 = 1024*1024 个虚拟页(高20位),虚拟页和物理页之间存在对应的关系,这种对应关系由进程的页表来维护。
i386采用二级页表:(单个页表太大 两级引用可以缩小占用内存)
第一级叫页目录(Page Directory,PD),可看作1024个页目录项(Page Directory Entry,PDE)组成的数组
- 每个PDE为4字节 用来找页表的位置
- 高20位为其对应页表在内存中的页框号(即其物理地址的高20位)
- 第0~2位为标志位,分别代表此PDE是否有效、对应页表映射的页中是否有可写的页、对应页表映射的页是否有用户程序可访问的
- 一个PD大小为4KiB,要求按页对齐(物理地址低12位全0)
- 每个PDE为4字节 用来找页表的位置
第二级叫页表(Page Table,PT),可看作1024个页表项(Page Table Entry,PTE)组成的数组
每个PTE为4字节 用来找具体页的位置
- 高20位为其对应的物理页的页框号(即其物理地址的高20位)
- 第0~2位为标志位,分别代表此PTE是否有效、对应物理页是否可写、对应物理页可否让用户程序访问
一个PT大小为4KiB,要求按页对齐(物理地址低12位全0)按页对齐就是指页表的起始地址需要是页大小的整数倍
地址转换流程
虚拟地址转换为物理地址的流程如下(此处忽略权限检查等过程,我们后面再介绍)
首先,将32位的虚拟地址(也是线性地址,假设是是扁平模式)分为三部分:
- 高10位为页目录号
- 中间10位为页表号
- 低12位为页内偏移量
1 | 31 22 21 12 11 0 |
分以下几步:
第一次,查询页目录项:
- 从CR3寄存器中取出当前页目录(PD,每个进程有一个)的物理地址:CR3的 高20位 即为其对应PD的页框号(即其物理地址的高20位),而PD都是按页对齐,其物理地址低12位为全0,据此得到所求PD的物理地址
- 得到所求PD的物理地址后,以虚拟地址的”页目录号“作为下标,查出其对应的页目录项(PDE)
第二次,查询页表项
- PDE的高20位即为其对应页表(PT)的页框号(即其物理地址的高20位),而PT都是按页对齐,其物理地址低12位为全0,据此得到所求PT的物理地址
- 得到所求PT的物理地址后,以虚拟地址的”页表号“作为下标,查出其对应的页表项(PTE)
第三次,查询最终地址
- PTE的高20位即为其对应物理页的页框号,也即虚拟地址对应的物理地址的高20位
- 虚拟地址对应的物理地址的低12位就是它的”页内偏移量“,将两个结果拼起来即为所求物理地址
权限检查
对内存的操作可以分为读和写两种,而此时CPU运行的状态也有内核态和用户态两种,对于这四种不同的内存操作,在地址转换时,对页目录项(PDE)和页表项(PTE)的标志位也有不同的要求,具体如下
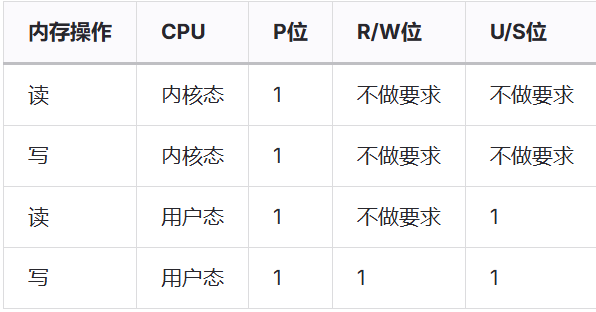
如果标志位不符合要求,CPU就会抛出Page Fault异常。注意权限检查在PDE和PTE阶段都会发生,因此如果用户想写某一页,即使这一页对应PTE的标志位是7(0b111),但如果PDE的标志位是5(0b101),也会抛出异常。
第一步就是要给内核一个页目录,这个页目录里包括[0, PHY_MEM)的恒等映射,这样才能在开启分页后继续访问内核的代码、全局变量、栈和剩下的堆区内存。也就是对这个区域内存访问时,是1:1原模原样恒等映射,不做复杂转换。(这个很关键 并不是所有地址都要转换。)
因为kernel大多数情况都是一页一页地要内存,所以只能按页分配的分配器已经足够大多数情况使用了,在这种情况下,我们可以很简单地使用单链表来管理内存,比如说采用下面的结构。
1 | typedef union free_page { |
我们把每一个空闲页的前4字节视作指向下一页的指针,或者NULL表示后面没有空闲页了,而free_page_list就是由空闲页组成的单链表。
分页机制的权限prot(即PDE和PTE的3个标志位合起来的值)
prot一般有5种:0(无效)、1或3(仅内核可读写)、5(内核可读写、用户只读)、7(内核和用户都可读写)
用户堆区管理
1 | int brk(void *addr); |
一次调用它是告诉操作系统现在堆区为空时程序的program break的位置在哪,后续调用就是请求操作系统把自己的program break的位置提到或者放到addr来,返回0代表成功,返回-1代表失败
program-break在哪?
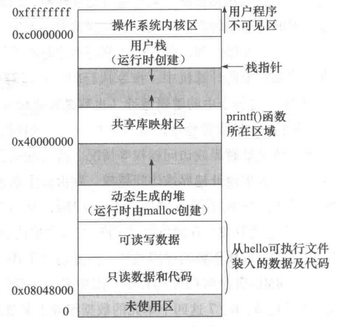
最开始就在可读写数据的顶端。它会向上增长,建立堆区。
如果new_brk比之前记录的brk高,就说明用户程序需要增长堆区,需要调用vm_map函数在当前页目录下创建[brk, new_brk)这段虚拟内存的映射(权限自然是7,用户可读写),**再记录当前进程的brk为new_brk**。(这样就相当于malloc在内存堆区申请了brk到newbrk的空间来使用)
如果new_brk比之前记录的brk低,就说明用户程序在降低堆区,那么降低的那一部分正如前面的各种内存回收函数一样,可以调用vm_unmap函数,再记录brk为new_brk(相当于free掉之前申请的区域)
多进程
进程是操作系统资源分配和调度的基本单位,是程序执行的实例,每个进程拥有一个进程控制块唯一标识。拥有自己的代码段、数据段、堆栈段。PCB用于保存进程状态,进程大体分为三个状态:就绪态、运行态、等待态。进程调度发生在ring0,而用户进程运行在ring1,当发生时钟中断时,可能进行进程调度。进程的保存和恢复都是通过PCB和寄存器的互动实现的。
PCB 不是处理器要求的,它是操作系统的实现者自己来构建的,一般包含包含进程名 id号 优先级 进程上下文 等等进程的各个属性信息,可以根据自己的需要来进行设计。
进程栈是为每个进程分配的一个独立的栈空间,存在于该进程的虚拟内存,即栈段,执行进程代码时,要使用这个栈。
既然多进程是要进行执行流的切换,就是要保存当前执行流的状态,然后让CPU加载另一个执行流的状态,等到换回来的时候就是让CPU恢复原来执行流的状态。因此我们可以利用中断处理机制来实现进程的切换。
每次中断的时候OS都会将当前状态作为一个中断上下文压栈保存在当前进程的内核栈(为啥能是当前进程的内核栈?因为当前进程在运行前,就将自己的内核栈信息放到了TSS中)里,我们记录一下这个上下文的位置(为什么记录?因为当前进程保存的上下文不是最新的,中断传入的上下文才是最新的。),然后不急着用这个上下文进行返回——我们用另一个进程之前保存的上下文进行中断返回,这就相当于切换到了另一个进程了。
1 | void schedule(Context *ctx) // 81号中断处理函数 进程调度 |
总结进程的切换过程:
首先初始化GDT中TSS和LDT的描述符,同时初始化TSS。
PCB中保存进程上下文,也需要被初始化。
然后通过iretd实现ring0到ring1的跳转:
- 首先设置进程表中第一个进程为正在执行的进程
- 然后设置esp为该进程的PCB首地址,准备将PCB中的上下文赋值给所有寄存器,(这里顺便设置tss中的esp0和ss0为PCB尾地址,即进程对应内核栈地址,进程控制块就在内核,方便之后从ring1跳转到ring0时保存现场(tss保存该进程内核栈地址,保存现场时直接按顺序压栈即可))
- 最后执行iretd会设置eip,cs和esp,ss,实现正式的控制流跳转。
ring1到ring0需要使用tss中保存的esp0和ss0:实际上就是,跳转契机设置为时钟中断发生时(也可以在一个自定义中断(又或者是一个系统调用内核函数)中进行进程切换,然后在时钟中断处理程序中对该例程进行调用,这与具体实现有关),总之利用中断实现进程切换。
- 中断发生时,找到对应中断门(CPU处理中断时,需要向当前进程核心栈内压入eflag eip cs(特权级变换则还有esp,ss 等等),执行对应中断历程。
- 所以中断执行时,先在tss中(保存了核心栈地址)取出当前进程PCB进程上下文尾地址(也就是核心栈地址),不断做push入栈保存现场(同时记录中断重入次数)。
- 然后设置esp为核心栈顶?,暂停时钟中断,允许其他中断。然后执行时钟中断handle程序。
- 在时钟中断处理handle程序中改变当前执行进程(真正的进程切换),最后再次重复上述的ring0到ring1,即可实现进程变换。
fork 进程复制
创建一个和自己状态相同的子进程,成功时父进程返回子进程的PID,子进程返回0;失败时返回-1。的“状态相同”,就是在用户态看来,fork刚返回时子进程和父进程的什么都是一样的——代码段一样、数据段一样、栈一样、正在执行的位置(EIP)一样、EAX以外的寄存器一样。注意上面的内存空间一样表示的是内容一致、虚拟地址一致而非映射到同样的物理地址,各个进程的内存空间是相互独立的。)唯一的区别就是EAX,也就是fork的返回值不同。
group_exit,wait进程退出
1 | void exit(int status) __attribute__((noreturn)); |
exit系统调用退出当前进程,并记录退出状态为status(一般放入main返回值),父进程可以通过wait系统调用获取子进程的退出状态。(进程将自己标记为ZOMBIE,不再参与调度)
1 | int wait(int *status); |
wait系统调用,寻找子僵尸进程,如果有,就释放这个进程的所有资源;没有就无限循环等着 返回一个退出的子进程的PID,如果status不为NULL,再把子进程的退出状态记录在那,最后释放这个子进程的PCB。
问题:进程有些资源其实是不能直接在退出时释放的,这是因为在处理exit系统调用时,CPU正在使用这个进程的地址空间、这个进程的内核栈,所以不能直接在exit里释放这些资源。
既然进程结束时自己处理不了后事,那就只能让它爹来给它收尸了,也就是等到它爹wait到它的时候再释放。
进程一生也要经历两次死亡——自己exit和它爹wait,exit只是标记这个进程不会再执行了,我们管这种已经退出、只等被它爹wait释放资源的进程叫僵尸进程,这也就是进程状态中ZOMBIE的意思。
进程通讯
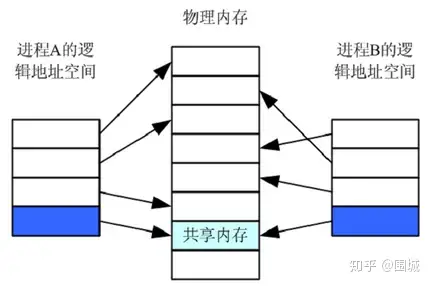
共享内存
进程的地址空间是相互独立的:虽然逻辑地址空间相同(比如所有用户程序都以0x08048000为入口),但是它们映射到物理地址空间中对应了不同的物理内存。
通过设置共享内存,实现内存在fork时会被共享给子进程,也就是父子进程的这个虚拟地址映射到相同的物理地址。
释放共享内存时,由于可能会有多个进程在访问这个共享内存页,所以当某一个进程释放该共享进程时,仅仅取消该进程对共享内存的绑定,而不能够直接释放该共享内存对应的物理页。只有当所有的进程都释放这一个共享内存时,该共享内存的物理页才能被真正释放。为了实现这一点,我们需要对物理页维护引用计数。
写时复制
在fork复制进程的时候,每一次都需要复制整个进程的地址空间的内容有点浪费了:对于大家都不写的内存,父子进程可以共用同一个物理页,就不用复制了。此外,有时候我们fork新进程之后会直接exec重新分配内存资源运行新的程序,这个时候fork还需要复制不要用的就内存就显得太过于繁琐了。
解决办法:我们可以在fork时让子进程地址空间映射到和父进程地址空间相同的物理页,不过两者都清除“写”权限,等到父子进程中的某一个要写内存,并由于权限触发页错误的时候,再申请一页新的物理页把内容复制到新的地址上去,我们称这种技术为写时复制
线程
线程是轻量级的进程,出现了线程之后,原本的进程就变为了主线程,不管是主线程还是一般线程,都是用进程控制块进行管理。进程控制块中有几个成员在线程控制中比较关键。
1 | typedef struct proc{ |
tgid是进程组的ID,一个进程组中的每个线程都共享相同的tgid,而tgid就等于本进程组中的主线程pid。
pid此时代表进程控制块的块号,每个线程都不一样。
为了更好地维护进程组中的线程,我们将同一个进程中的线程控制块以链表的形式组织起来,链表的指针就是proc_t中的thead_group变量,如下图所示:
1 | +-------------------------+ |
而groupLeader就是本进程组中的主线程指针。
进程组中的资源由主线程统一管理。例如:内存空间,信号量,堆区,打开文件。但是有独立的用户栈,内核栈,和进程上下文。
clone系统调用:创建线程
1 | int clone(int (*entry)(void*), void *stack, void *arg); |
entry函数执行完成后,就执行线程的exit函数退出线程。(可以设计传入一个函数指针ret专门就进行线程的结束,让clone执行完毕后,执行这个ret,取出存放在%eax里面的返回值并调用exit,打扫战场,这样就可以避免在entry函数中显式使用exit函数,而是直接return就行)
线程退出thread_exit
普通线程退出只需要标记自己为ZOMBIE,不参与调度即可。但是进程就需要标记自己的同时,负责将本进程下所有的僵尸线程进行回收。程序无法自杀,这在前面提到过。所以需要父进程回收子进程,主线程回收其余线程。
如果进程不是最后一个死去的,死之前还有线程活着,那么进程就要循环等待,直到线程都死光,然后释放他们。
注意:group_exit和exit所有线程都能调用,区别在于,前者直接将本进程组中所有的子线程释放,然后标记进程为僵尸(退出整个进程,而且负责了子线程资源回收);而后者会根据调用者的身份进行处理:子线程则直接标记为ZOMBIE,主线程则准备释放所有子线程并标记自己为ZOMBIE(注意,如果子进程没死,则不会强制释放,而是会等待)。
所以:thread_exit或者说exit则仅仅退出一个线程,进程的资源不会因为线程的退出而回收,而是**等到进程中的所有线程都退出,或者某个线程显示调用了exit**(包括主线程通过return)退出,才结束进程回收资源。
所有线程都能进行wait系统调用,但是只会对线程所在的进程组主线程进行操作:查看主进程的子进程是否为ZOMBIE、是否可以释放。
之后有关资源分配的api都要到主线程的方向上去做。
线程同步
线程的新增成员:
1 | typedef struct proc{ |
join
让父线程等待子线程完成,实现线程之间的同步,并在子线程结束后手动回收资源。适合需要严格同步的场景
举例来讲,在一个文件处理程序中,主线程需要创建多个子线程,每个子线程负责读取不同的文件并处理数据。主线程必须等待所有子线程处理完文件后再继续执行汇总结果的操作。在这种情况下,主线程可以使用join来等待所有子线程结束,以确保文件处理任务都完成后再继续执行汇总任务。
1 | int join(int tid, void **retval) |
首先join的调用者不能是被join的对象。然后让当前线程P一下目标线程的join_sem, join_sem的初始值为0,此时当前线程就会等待目标线程。等到目标线程运行结束,需要修改 proc_makezombie,在函数的最后V一下自己的join_sem`,唤醒可能等待在它上面的线程。(先别急着死,可能还有人在等你)
由于线程总会通过thread_exit退出,退出的状态记录在控制块的exit_code当中,所以如果retval不为NULL,将目标线程的**exit_code赋值给retval指向的内存**即可。(下面的抽象操作)
1 | if (retval != NULL) |
detach 脱离
使子线程独立运行,不需要父线程等待,系统会在子线程完成时自动回收资源。适合非同步场景。
在一个网络服务器中,每当有客户端连接时,服务器会创建一个新线程处理该客户端的请求。由于服务器不需要等待每个客户端的请求完成,且这些线程的生命周期不需要被服务器管理,因此可以使用detach让子线程自行处理客户端请求并在结束时自动释放资源,从而避免服务器阻塞。
sys_detach设置控制块中的detached=1与joinable=0变量(detach之后的线程不能join),detach之后的线程在退出时不等待主线程释放自己的控制块,而是直接释放控制块。所以我们需要据此修改sys_exit的逻辑。
问题是:不是父进程回收,那么谁回收?答案是内核进程。设置该线程的parent为内核进程,同时内核进程添加一个扫描ZOMBIE线程的过程即可完成。顺便还能把parent先死的孤儿进程进行回收(wait做不到这点),可谓一举两得。
异步通信 信号机制 Signal
信号则是传递短消息的简单通信机制,通过发送指定信号来通知进程某个异步事件发生,以迫使进程执行信号处理程序。信号处理完毕后,被中断进程将恢复执行。
信号可以通过异常(硬中断)产生,如进程执行非法指令或段错误(大名鼎鼎的Segmentation fault)等,内核会发送SIGKILL或SIGSEGV信号;进程也可以发出信号,实现进程同步与中止,如SIGKILL信号将强迫另一进程终止。我们的实验中主要模拟进程发出的信号。
信号一般分为操作系统标准信号和应用进程定义信号,这种机制模拟硬中断,但不分优先级,通信双方不必事先联系,简单且有效,但不能传送数据,故能力较弱。
进程信号相关新成员:
1 | typedef struct proc { |
信号处理流程:
- 信号的产生
用户进程通过
kill()系统调用向自身或其他进程发送信号。所以上一周我们实现的kill系统调用是一个望文生义的简化版,调用kill就是杀死一个进程。但实际上,在Linux系统中kill用来发送信号,只有当发送的信号恰好是SIGKILL时,才会杀死指定的进程。硬件异常(如段错误
SIGSEGV、浮点运算错误SIGFPE)会触发相应的信号。在我们的实验中我们不考虑这种情况,我们假设所有的信号都是用户进程通过kill发出的。用户终端输入某些控制命令(如
Ctrl+C触发SIGINT)。我们也不考虑这种情况。
当信号被产生时,它会被记录在目标进程的 信号等待队列(sigpending_queue) 中。
信号的阻塞
在信号等待处理之前,进程可以通过信号屏蔽字(
sigblocked)来决定是否屏蔽某个信号。如果该信号对应的位在sigblocked中被设置,信号会被阻塞,直到信号解除阻塞为止。这时信号会暂时保留在sigpending_queue中。进程可以使用sigprocmask()系统调用来阻塞或解除阻塞某些信号。信号的处理
当信号不再被阻塞,内核会在合适的时机执行信号的处理过程:
用户自定义处理函数: 如果进程通过
sigaction()系统调用为该信号设置了自定义的处理函数(存储在proc_t中的sigaction[]数组中),内核会在信号触发时调用该函数。自定义处理函数可以执行任何用户定义的操作,例如输出消息、修改状态等。默认处理: 如果进程没有为信号设置自定义处理函数,内核会按照信号的默认行为处理。不同信号有不同的默认处理方式,例如:
SIGKILL会直接终止进程。SIGSTOP会暂停进程,而SIGCONT会恢复进程的执行。
默认处理的方式在handle_signal中实现
信号的递送: 内核在进程恢复执行用户态代码之前,通过
do_signal()函数检查sigpending_queue中的信号。如果有未被阻塞的信号,内核会调用信号处理函数执行相应操作。该过程通常会在上下文(进程)切换(proc_run)时发生。do_signal和proc_run需要在后面修改。
信号的返回 信号处理完成后,进程会继续执行被中断的代码。系统在调用信号处理函数时,保存了进程的执行上下文,因此信号处理完成后可以安全地返回到信号之前的状态。在真实的Linux系统中,大部分信号处理程序会在用户态完成(因为涉及到访问用户地址空间),所以在信号处理程序执行结束之后会通过
sigreturn返回内核态做一些善后工作。我们在实验中可以省略这一步,因为在分页那里为了好操作我们把内核的地址都映射到每个用户进程的地址空间中,所以这一步的地址切换与相关的善后工作就都可以省略。信号的特殊处理 某些信号是不可被捕获或忽略的(如
SIGKILL和SIGSTOP)。这类信号的处理逻辑通常直接由内核完成,进程无法改变它们的行为。在实验里,我们约定SIGKILL,SIGSTOP和SIGCONT三个信号的处理会立即处理,而不是挂载到sigpending_queue上之后等待上下文切换时处理。信号的处理时机 信号并不会立即被处理。信号的处理时机通常是当进程即将进入用户态或从中断返回时,通过
do_signal()函数检查并递送。如果信号已经被阻塞,它们将会被保留在sigpending_queue,直到解除阻塞时才会处理。
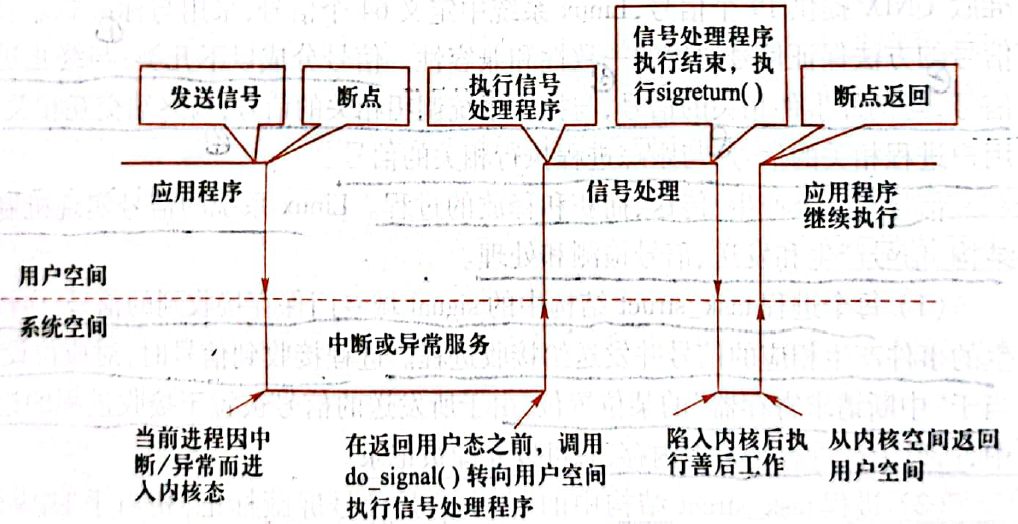
除了善后工作不用做,剩下的都需要实现。
虚拟文件系统
文件是由文件名标识的一组信息的集合,或者说白了就是一个字节序列。类Unix系统中符合这个要求的就是文件,甚至没有文件名也行,也就是所谓的 “万物皆文件”
都是字节序列,操作系统就都能当做文件统一管理。管理这些文件的就是虚拟文件系统(抽象层)。用户API也能用统一的方式访问文件,比较方便。而在底层实现时(实现层),要根据不同类别文件进行个性化处理。

这里以处理磁盘文件和设备文件为例。
虚拟文件系统要建立在磁盘文件系统和设备文件系统等等底层系统来实现。磁盘文件系统是根据文件的inode来进行操作,磁盘文件的读写可以使用iread、iwrite来实现(这些都是磁盘文件系统api),而设备文件的读写就要根据具体的设备文件类型来决定。设备文件有独特的类型:有自己的read和write函数指针。
如对于串口的读写就可以直接变成用户对对应设备文件的读写,然后在底层操作系统调用他们自己的读写函数实现读写。
磁盘可以分为以下几部分:主引导记录MBR,各种分区(每个分区可以使用不同的文件系统)。而每个分区可以有文件系统的元数据+数据区(这是最重要的,剩下的可能还有引导扇区,空闲块,日志区)。不同的文件系统设置元数据的方案,或者是数据的组织管理方案是不同的。例如ext文件系统使用超级块+inode表,而NTFS使用MFT(主文件表),FAT32使用目录项+数据区的簇来管理。
inode有动态和静态之分,在磁盘上是静态的inode(主要是数据的扇区位置,长度,文件名,持久化数据)。而在操作系统中放置的是动态inode(文件是否可用,随运行变化)。操作系统会保存一个活动inode表,在操作系统启动时进行初始化,在打开文件时进行录入,减少访存次数,提高性能,关闭文件时就释放inode。但是由于本操作系统太过简单,直接就能把所有的文件都初始化时录入该表中,然后进行操作。
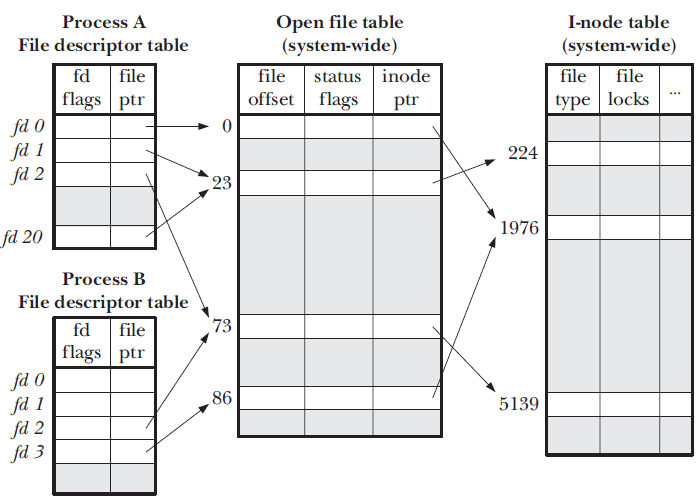
系统打开文件表:OS维护一个系统中所有被打开的文件表,里面存储文件指针。这是供虚拟文件系统使用的文件类型。磁盘文件系统提供的api都是针对inode实现的。而虚拟文件系统不应该关注底层实现细节,不管底层是什么文件系统都能实现调用,所以不能直接操作inode类型。虚拟文件系统提供一系列api来对文件进行操作。
用户打开文件表:每个进程维护一个文件表,存入已经打开的文件指针。通过编号进行下标访问,编号就是文件描述符fd,进程可以通过fd访问文件指针,也可以分配一个位置存储文件指针,表示打开一个文件。
抽象层次: 对inode操作(磁盘文件系统)——对file_t操作(虚拟文件系统)——通过系统调用操作文件(系统调用)
Tip:函数指针
1 | // 下面是一个函数,参数中有函数指针类型的变量,如entry就是一个变量,存储函数指针 |
- Title: 操作系统概念总结
- Author: HangYF
- Created at : 2025-02-17 14:12:22
- Updated at : 2025-02-17 22:14:24
- Link: https://redefine.ohevan.com/2025/02/17/操作系统概念总结/
- License: This work is licensed under CC BY-NC-SA 4.0.